



Next: Exhaustive Rule Learning -
Up: Learning Sets of Rules
Previous: Variation
- 1) Sequential Covering Algorithms learn one rule at a time,
remove the covered examples, and repeat. Decision trees can be seen
as Simultaneous Covering Algorithms.
- Sequential covering algorithms perform n*k primitive search
steps to learn n rules each containing k attribute-value tests.
If the decision trees is a complete binary tree, it makes (n-1)
primitive search steps where n is the number of paths (i.e., rules).
- So Sequential Covering Algorithms must be supported by
additional data, but have the advantage of allowing rules with
different tests.
- 2) General to Specific or Specific to General - general to specific
starts at the one maximally general hypothesis - in specific to
general there are many maximally specific hypothesis (the training
data). Golem chooses several randomly and picks the best learned hypothesis.
- 3) ``generate then test'' or ``example driven''search for legal
hypothesis - in gtt hypothesis performance is based on many training
examples so the effect of noisy data is minimized
- 4) In either system rule post-pruning can be used to increase
the effectiveness of rules on a validation set.
- 5) rule performance measures - relative frequency (accuracy)
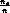 - m-estimate of accuracy
- m-estimate of accuracy 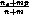 -
entropy
-
entropy 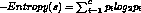
Patricia Jean Riddle
Wed Jun 23 13:06:34 NZST 1999