



Next: Summary
Up: Reinforcement Learning
Previous: Generalizing from Examples
- agent posses perfect knowledge of the functions
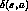 and
and 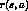
- Focused on how to compute the optimal policy with the least
computational effort, assuming the environment can be simulated
- Q learning has NO knowledge of the functions
and
- Focused on the number of real-world actions the agent must
perform to converge to an acceptable policy
- in many practical domains , such as manufacturing problems, the
costs in dollars and time of performing actions in the external world
dominate computational costs
Patricia Jean Riddle
Wed Jun 23 13:06:34 NZST 1999