



Next: Temporal Difference Learning
Up: Reinforcement Learning
Previous: Updating Sequence
- The functions
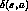 and
and 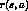 can be viewed as
first producing a probability distribution over outcomes based on
can be viewed as
first producing a probability distribution over outcomes based on
 and
and  and then drawing an outcome at random according to
this distribution - nondeterministic Markov decision process
and then drawing an outcome at random according to
this distribution - nondeterministic Markov decision process -
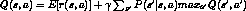 , but is not guaranteed to converge
, but is not guaranteed to converge - decaying weighted average of the current
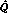 and the
revised estimate
and the
revised estimate -
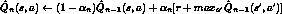 , where
, where
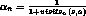
- convergence long = 1.5 million games in Tesauro's backgammon program
Patricia Jean Riddle
Wed Jun 23 13:06:34 NZST 1999