



Next: Remarks on Locally Weighted
Up: Instance-Based Learning
Previous: Remarks on k-nearest neighbor
- construct an approximation
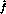 from the training
examples in the neighborhood of
from the training
examples in the neighborhood of 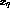 , then calculate
, then calculate
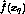 , then can be deleted.
, then can be deleted. - assume that our function is a linear function,
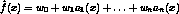
- Possible error methods for gradient descent
-
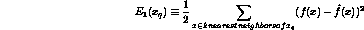
-
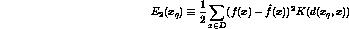
-

- criterion 2 is nice because allows every training example to
have an impact, but computation grows linearly with the # of training
instances
- criterion 3 is a nice compromise
- the gradient descent training rule becomes
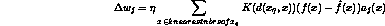
- but many more efficient ways are available to directly solve for
the coefficients
- Why won't these work for ANNs?
Patricia Jean Riddle
Wed Jun 23 13:06:34 NZST 1999